
*학부 연구생(2021~2023) 시절 논문 세미나 때 발표한 논문에 대한 간단한 설명과 발표 자료입니다. 따라서, 학부생의 해석이기에 내용 오류나 오타가 있을 수 있으니 이해 부탁드립니다!
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
Han, Song, Huizi Mao, and William J. Dally. "Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding." arXiv preprint arXiv:1510.00149 (2015).
논문 설명
Deep Compression은 모델 압축을 이용한 네트워크 경량화 기술 중 하나이다.
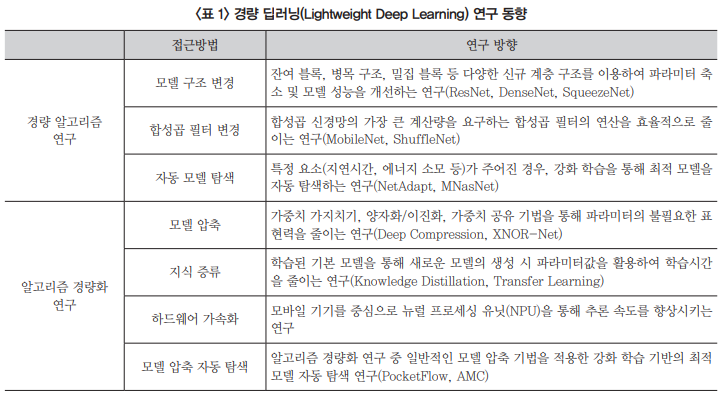
논문 제목에서 알 수 있듯이 3 단계로 이루어진 경량화 기법으로 작은 값을 가지는 가중치(weight)를 없애는 Pruning과 적은 비트 수로 가중치를 표현하는 Quantization, Huffman coding을 사용하여 적은 비트 수로 가중치를 표현하는 Sharing 단계를 거쳐 모델을 경량화한다.

분류에 대하여 실험한 결과, AlexNet 모델에서 정확도 손실 없이 35배(240MB to 6.9MB)를 압축하였고 VGG-16의 경우 49배(552MB to 11.3MB)나 압축하였다.
논문 발표일
2021년 3월 26일
발표 자료
+) 이 논문은 학부 연구생을 시작하고 처음 읽었던 논문이자 처음 발표를 했던 논문이다(그래서 그런가 발표 자료도 허접하다). 당시에는 논문을 읽고 이해하기가 무척 어려웠는데, 꾸준히 읽다 보니 지금은 어느 정도 논문을 읽는 노하우가 생겼다. 개인적으로는 이 발표 이후부터 본격적으로 연구에 재미를 붙여 나의 첫 논문도 작성할 수 있었기에 감회가 새롭다.
'Papers > Model Lightweight' 카테고리의 다른 글
| [Review] Deep Mutual Learning (0) | 2023.09.16 |
|---|